In the previous post of this series, we tackled how to land inbound emails routed to an entire domain using SES, a Lambda function, and an S3 bucket. As the whole point of these posts is parsing image-based documents of invoices using AWS Textract, you’re probably wondering how we get from files in S3 to magic, OCR-extracted text. This post gets us most of the way there, addressing some points of improvement on our original solution. In addition, we add the function to our serverless application in this post that actually gets our extracted text back from Textract. In a future post, we’ll stand up a DynamoDB table for storing our outputs and then look at ways to interact with the data we’ve stored there.
This is the part of the story where I admit that my original design was a bit short-sighted. And yep, it’s been a few months since the last post – while part of me wants to feel guilty for not closing the loop here a bit sooner, honestly I’m witholding the apology because those few months have provided some valuable insight in terms of general, overall usage of having my email routed to an S3 bucket. There’s really only a single address on that domain I care about (as many of my domain registrations use it). The rest are tied to some sort of automation (as is the case here), or just receive junk that I rifle through occasionally.
My original design considered receiving mail for only a certain prefix (or a facade that I only care about the mail of a certain prefix) vis-a-vis the entire solution. In reality, that’s not the case at all. My primary emails I still want to read – while I’ve used the S3-copy-to-local-and-read-with-mutt solution outlined in the first post a few times (yeah, it’s painful), I’m thinking long-term I may just want to forward messages from the primary handle on to a personal Gmail account. For other addresses that could potentially serve other automation-based needs, I’d probably want to send them on to some other processing stream. In my mind, the better way to architect this solution overall is to build a distribution system based on routing messages to whatever workflows they need to be routed to, based on the prefix (handle, etc. – whatever you want to call it) that the original message is sent to. SNS seems like a perfect candidate for this.
I’ve modified the inbound-ses-processor Lambda to accept a JSON dictionary as an environment variable. This dictionary maps email prefixes to a list of SNS ARNs that the message ID is forwarded on to after it is landed in S3. If the message has attachments, those S3 prefixes are sent in the drop to SNS as well. This pub-sub pattern lets me subscribe whatever downstream logic I want to SNS ARNs that correspond to any given email prefix. I don’t really see a use-case now for more than a single publisher to exist for a given prefix, but the solution I’ve designed allows for the possibility that multiple workflows may be desirable in the future (hence the mapping is prefix to list of ARNs, not just prefix to single ARN). For now, I’m setting up a single topic (list of one ARN) and mapping it to the auto-maint@ handle. I send a message to auto-maint@, it gets landed in S3, and attachements are stripped and landed in S3 as well by the inbound-ses-processor function. That same function then looks to see if any publishers (i.e. SNS topics) exist for this prefix in the mapping, and pushes a message to those topics for other downstream subscribers.
Here I introduce the new auto-maint-to-textract function. Using our new pub/sub capabilities, I pick up all the attachments on a message inbound to auto-maint@ and ship them off to Textract for processing. That Lambda function waits for the message to come back from Textract, then pulls out the bits I care for from the OCR’d document. For now, the function logs that output to CloudWatch; but, as mentioned, we’ll get that data plugged into a DynamoDB table in the next post.
In the meantime, I’ve revised the architecture diagram to reflect the new reality of the solution.
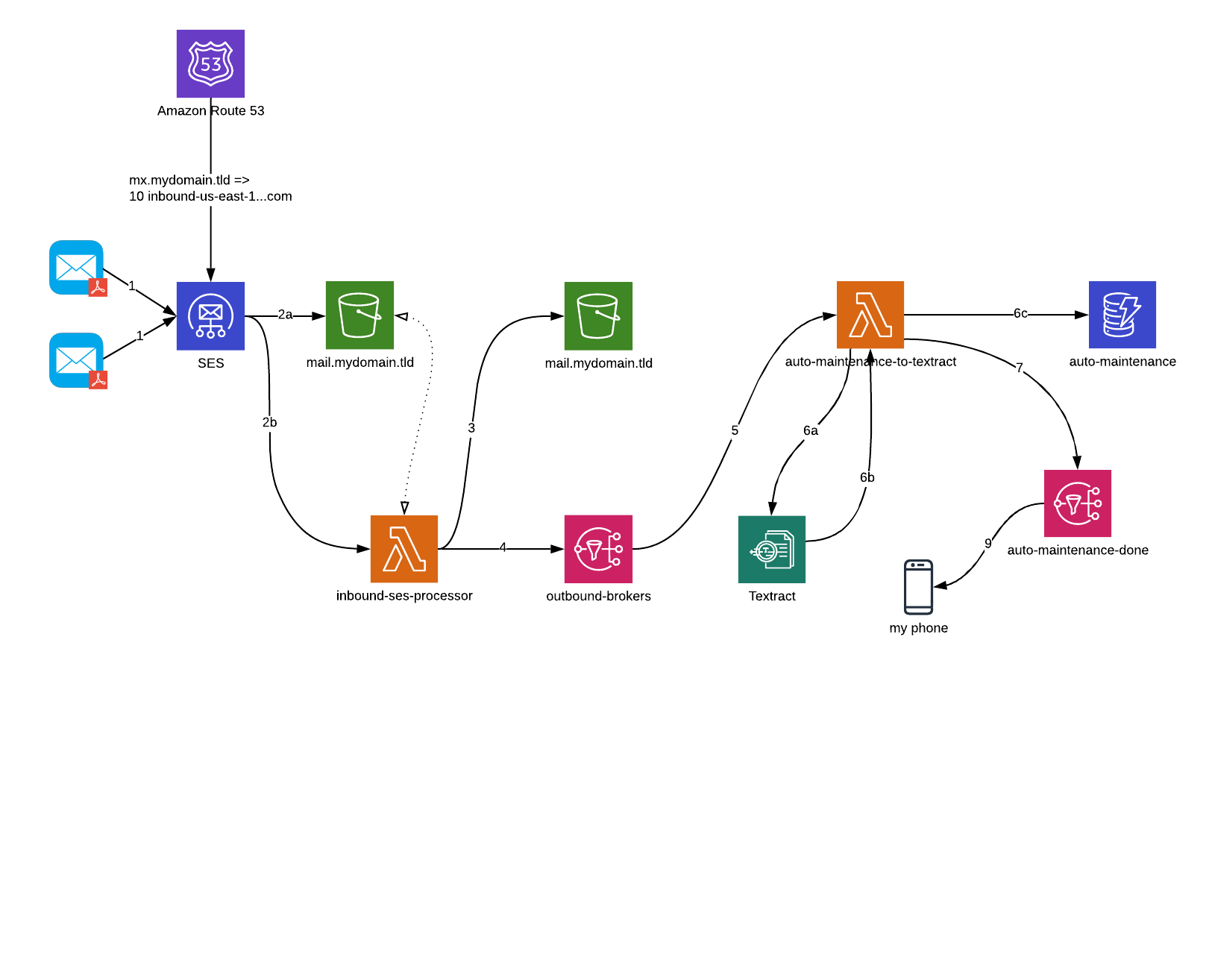
The updated code is here. I’ve cleaned the code and the Serverless template up a bit – names of objects will be different now, so you may have to reconnect SES to the newly-recreated inbound-ses function.
Until next time!