Posts

Travel: Favorite Restaurants
I’ve had the good fortune of traveling quite a bit recently. I’m no connoisseur, but I do like a good meal. As I come across a great restaurant, I’ll make a note of it here. Austin, TX Moonshine Grill: I had the Green Chile Macaroni and a friend had the Chicken & Waffles (both of us greatly enjoyed our meals). Atlanta, GA DBA Barbeque: I had the Archie Bunker (it was great).
Getting Kubernetes Certified
My goal for Q1 2019 is to add the Certified Kubernetes Administrator certification to my resume. In regards to writing about previous certification experiences, I have either: written a general outline of the experience much later not written about it at all, or just posted my study notes After more or less every certification, people have asked me what I did to prepare for the certification. Generally, the answer has been some combination of “practical experience and watching the A Cloud Guru course.
Thoughts on the AWS ML (Beta) Exam
I was able to squeeze in the beta AWS ML exam the week before Christmas. Given that it was several weeks ago, some of the other resources on Medium may be more informative, but I’ll throw my two cents out here for anyone who may be interested. Generally speaking, know about different types of machine learning models (particularly those supported by SageMaker) and in what sorts of situations they’re applicable. These include:
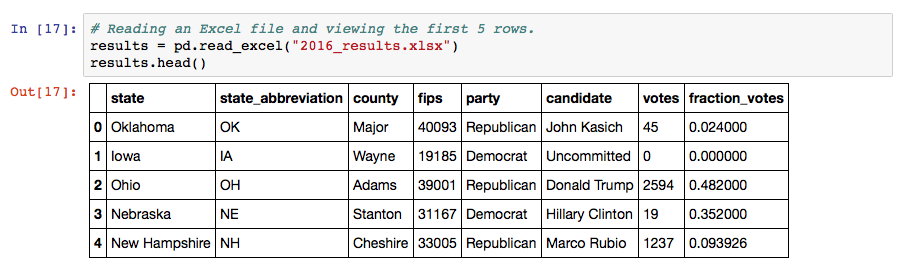
Some of My Favorite Pandas Snippets
I have spent the last six months working on the migration of multiple (mostly) SQL-based data sources to a multitude of different AWS-based targets, ranging from conventional SQL backends to user stores like Cognito. Many (if not all) of these efforts involved joining and coalescing data from multiple sources (per single data set) to migrate to a single backend system. For the majority of the work, I used Jupyter notebooks – relying heavily on Pandas and Numpy – for source data analysis, transformation, and load into target systems (as well as the use of database-specific client connection libraries, including MySQL, MS SQL, and Redshift/Postgres).

Working With Azure AD in AWS and Moving from Azure SQL to RDS SQL Server
For the last week, I worked on a pretty intense migration of a fairly sizable Azure SQL instance that moved into AWS’ RDS service (running SQL Server). It was an intense project due to the timeline and size of the database. Of course, this involved access to both services, using both web consoles, CLI and native database interfaces. The client was controlling access to AWS and Azure using Azure AD, so I had to figure out federated access to the AWS API/CLI (since we built out their new environment using Terraform).
Terraform: Conditional Outputs in Modules
There are several drastic HCL improvements forthcoming in version 0.12 of Terraform, but after an issue I encountered this week while creating some infrastructure with an 0.11.x version of the runtime, I wanted to cover the issue, how to remedy it in versions < 0.12, and talk about how (I believe) the issue will be remedied thanks to some of the 0.12 improvements. Basically, this type of issue will manifest itself as an error during the plan phase with this form of error message: module.

Terraform Provider Bundling
Beginning with the 0.10.x version tree of Terraform, HashiCorp decided to decouple providers from the main Terraform runtime (see the 0.10.0 CHANGELOG for details). For a lot of users, this is a seamless win as Terraform will pull down whatever providers it deduces that it needs to execute your build assuming you have network connectivity to reach their servers and grab the files. This flexible architecture allows new providers to be released, bugfixes and features to be introduced in existing providers without requiring a version increment and download of a monolithic Terraform package.

Curated Lists - My Favorite "DevOps" Tools (and Then Some)
First off, forgive the title. I fall much more on the side of “devops” as a cultural mindset than a thing we do, but when it comes to searching for and exposing things for search on the interwebs, I’m going with the status quo. Next, a few caveats: I haven’t used every single one of these to great extent (or some even at all), but they are tools that are on my radar.
One-Liners - Get AWS AZ Counts
OK, so not truly a one-liner, but a nice quick-n-dirty way to get a count of all active AZs for each region for your AWS account. echo -e "$(tput bold)Region | # AZs$(tput sgr0)" for region in $(aws ec2 describe-regions | jq -r '.Regions[].RegionName'); do num_azs=$(aws ec2 describe-availability-zones --region ${region} | jq -r '.AvailabilityZones | length') printf '%-15s | %5s\n' ${region} ${num_azs} done This requires jq and the AWS CLI to be installed.
Datadog API in Docker Containers Needs a Hostname
Lately I’ve had the good fortune of working on an app migration effort with a heavy focus on containerization, specifically a couple of batch processes which run daily. Formerly, these processes were run by an enterprise scheduling system which handled alerting. After deciding to rewrite the batch processing functions and containerize them, that left me short alerting. I decided to implement a new alerting solution using Datadog, since we’re already using it to gather metrics for the main application.